







































Have you ever found yourself in a situation where you need to extract text from a PDF but don’t know how? It’s not just you. Pros in all fields now use PDFs as their preferred file type. However, extracting information from them may take time and effort. Fortunately, there’s new tech that can help.
This article will discuss how to extract text from pdf in five easy stages. This post will show you how to effectively remove text from your PDFs, whether you’re a business owner, student, or legal expert. We will also discuss PDF automation best practices to help you organize your workflows and save time. Let’s start learning how to extract text from PDFs like a pro!

What is intelligent document processing?
The way that organizations process their documents is changing thanks to the game-changing technology known as intelligent document processing. Simply said, IDP uses several cutting-edge methods and technology to enable the automatic processing of documents.
Optical character recognition, which lets computers to recognize text in an image or scanned document, is one of the essential elements of IDP. For example, financial institutions and government organizations can use this technology to extract information from documents swiftly and reliably.
IDP uses machine learning and natural language processing in addition to OCR to automate document workflows. While NLP enables computers to interpret and comprehend human language, you may train ML algorithms to spot patterns and make predictions based on data. IDP can assist businesses in classifying documents, extracting data, and automating workflows more effectively and precisely by fusing different technologies.
IDP offers a wide range of advantages. By automating repetitive and laborious document processing operations, IDP can benefit businesses by saving time, lowering expenses, and increasing accuracy. IDP, for instance, can automatically extract the necessary data from invoices or contracts and add it to a database or accounting system instead of manually entering it.
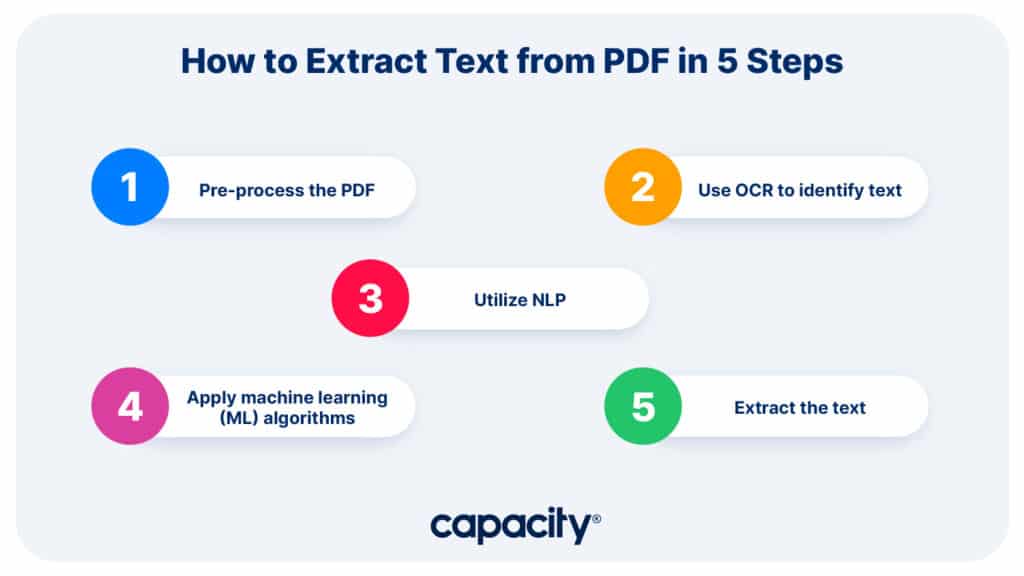
How to: Extract text from PDF in 5 steps
Automating the process of extracting text from a PDF can be challenging. Follow these steps to help you start the process:
Step 1: Pre-process the PDF
Make sure you check all necessary processing and formatting have been handled before you extract the text. Pre-processing involves checking file compatibility, optimizing images and documents, and removing any embedded audio or video files.
Step 2: Use OCR to identify text
You can use OCR technology to recognize and isolate text from the document after the PDF is pre-processed. OCR also helps identify different fonts, sizes, and text styles to extract data points accurately.
Step 3: Use NLP
Natural Language Processing (NLP) technologies enable computers to comprehend human language. It can help identify the PDF text’s key phrases, terms, and concepts. This allows you to extract only relevant information from the document.
Step 4: Apply machine learning (ML) algorithms
Train the ML algorithms to recognize patterns or classify documents according to pre-defined criteria. With a combination of OCR and NLP technologies, you can use ML algorithms to detect and classify text more accurately.
Step 5: Extract the text
Finally, you can use the extracted information from your PDF documents to automate various tasks such as data entry or invoice processing. By using IDP technologies to extract text from a PDF, businesses can streamline their document workflows and save time by automating tedious tasks.
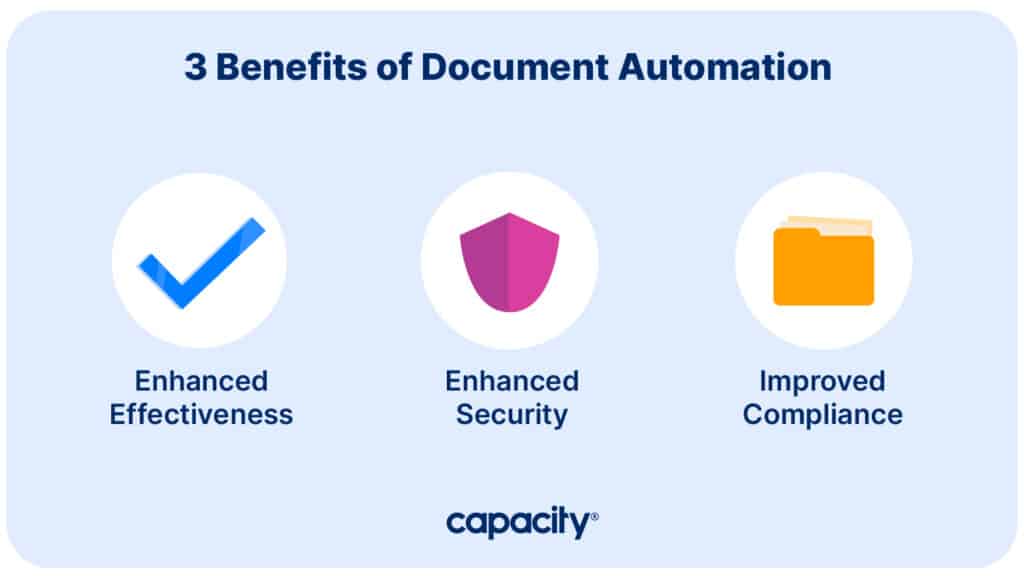
Benefits of document automation
Automating document processes offers organizations several benefits that can significantly impact their business. This section will review some of the critical advantages of automating document activities.
Enhanced Effectiveness
Document automation benefits businesses in various ways, including enhanced productivity and accuracy. Automating document activities results in increased efficiency by reducing manual labor and eliminating repetitive tasks such as data entry or text analysis. This allows teams to focus on core tasks while still getting the job done faster than ever
Enhanced Security
Businesses can benefit from automation to manage and safeguard their documents more effectively and lower the risk of data breaches and illegal access. Organizations can control who can access private information and ensure that papers are preserved securely by automating document procedures.
Improved Compliance
Organizations can ensure their documents adhere to relevant regulations and standards by automating document processing. By automating compliance checks, organizations may ensure their documents comply with legal requirements and avoid paying heavy fines. Businesses that operate in industries with stringent laws, like banking or the healthcare industry, must have it.
Extract PDF text best practices
Text extraction from a PDF might be time-consuming, especially if the document you’re working with is extensive. But following a few best practices can streamline and accelerate the process.

Let’s look more closely at a few of the best practices:
- Use a high-quality PDF: The quality of your PDF can impact the accuracy of the text extraction. Ensure the PDF has high quality and resolution, with no blurring or smudging.
- Preprocess the PDF: Preprocess your PDF to ensure it’s readable. Start by cleaning up the text, removing headers and footers, and then converting images to text.
- Use an accurate OCR engine: Choose an Optical Character Recognition engine designed for PDFs. And then, ensure it’s trained on the specific font and language of the PDF.
- Choose the correct extraction method: There are several methods for extracting text from a PDF, like pattern matching, semantic extraction, and layout analysis. Choose the most appropriate process for your PDF.
- Train your IDP model: If you’re using an IDP system, train your model on a large dataset of PDFs to improve its accuracy.
- Check the output for errors: After extracting text, check the output for errors and make corrections where necessary. This is especially important if you use the extracted text for further processing or analysis.
- Validate the extracted data: Once the text has been extracted, validate the data against the original.
- Use a validation workflow: Implement a validation workflow that lets you review and correct errors in the extracted text manually.
- Monitor performance: Regularly monitor the performance of your IDP system to ensure it’s extracting text accurately. This may involve analyzing metrics like precision, recall, and F1 score.
- Continuously improve: Continuously improve the performance of your IDP system by updating the OCR engine, refining the extraction methods, and training the model on new data.

Automate Your Work
Capacity’s enterprise AI chatbot can help:
- Answer FAQs anytime, anywhere
- Find relevant documents within seconds
- Give surveys and collect feedback
How to automate PDF text extraction with Capacity to improve the customer experience
Capacity is an intelligent document processing platform that helps companies streamline their document workflows and improve their customers’ experiences. With Capacity, businesses can automatically extract text from PDFs quickly and accurately, enabling them to process documents more efficiently than ever before.
Capacity’s IDP technology allows organizations to instantly extract information from PDFs, documents, invoices, contracts, etc., and add it to a robust knowledge base. This data can be used to automate support for internal team members and external customers.
Although extracting text from a PDF might be time-consuming, it can be completed quickly and simply with an all-in-one platform like Capacity. Organizations can streamline their document processes and increase productivity, all on one platform that does it all.
Want to see the power of Capacity for yourself? Try it today for free!



