







































Big things are shaking at the intersection of natural language processing and machine learning.
Modern machine learning techniques have captured the public’s imagination by making huge strides in the computer vision field. Vision tasks like facial recognition, medical imaging diagnosis, and self-driving vehicles have all been brought into the mainstream in the last few years.
Today, the stars are aligning for Natural Language Processing tasks as well. As a practitioner of NLP technologies on the Capacity research team, I am constantly monitoring the state of the industry for new tools and techniques that we can apply to make the Capacity platform smarter—better able to answer business questions and organize business information. It’s exciting to see that NLP is leaping forward with similar advances to computer vision with respect to modeling techniques, compute power, and available training data.
The ImageNet moment.
Computer vision tasks leveled up in 2009 when the ImageNet data set was published; the first of its scale and magnitude: a hand-labeled collection of over 14 million images from the Internet with descriptions and labels of specific items within the images. Did you ever have to prove your identity by identifying a set of images in a CAPTCHA? You may already have helped train AI systems by labeling this computer vision data.
You may already have helped train AI systems through a “CAPTCHA” (Completely Automated Public Turing test to tell Computers and Humans Apart)
Given all this well-organized, hand-labelled data, the vision algorithms at the time began to work significantly better, but the real leap ahead came in 2012 when researchers combined the dataset with a “deep” neural network. Being “deep” here means that the network has many layers of interconnected, nonlinear calculations, like neurons in the human brain, such that it is able to stack and remember complex patterns and outcomes. Almost magically, deep nets could continue increasing their performance by simply feeding them more and more training data. This is in contrast to traditional algorithms that would eventually plateau regardless of the amount of training data. The first such deep learning model absolutely crushed the previous state of the art, beating its accuracy score by a full 41 percent and kicking off the current explosion of deep learning across academia and industry.
NLP’s ImageNet moment.
In the hands of curious, cross-training researchers, these new methods made their way into language labs and began to upend decades-old paradigms and spur new progress. NLP’s “ImageNet moment” had arrived, as one NLP researcher Sebastian Ruder described in a popular industry article.
Previously, traditional NLP models sought to write complicated sets of grammatical rules and decision trees. The infinitely-bending structures of human language would run roughshod over them with punishing edge case after edge case that they could not handle. Other traditional NLP algorithms were probabilistic language models, which simply try to predict the next word based on the previous word. These too would break down by not having a broader context for the situation than the previous word and chain of prior probabilities. To be fair, all these methods were (and still are) useful at certain tasks and remain good baselines and starting points, but machine learning methods are upping the game dramatically.
I’ll dig into a number of these new NLP algorithms with machine learning roots—from word2vec to ELMO—in a forthcoming article. For now, I want to focus on the newest model from the folks at Google AI Research known as BERT (Bidirectional Encoder Representations from Transformers). In the steady stream of papers that advance the state of the art, this one published only a few weeks ago is being called by some the best NLP model ever.
Better than humans at answering questions.
This model uses new architectures and new training techniques to train a powerful, general-purpose language model that can be fine-tuned and transfer-trained easily for specific tasks. The authors fine-tune the output layer of the model in several, flexible ways to perform the various tasks on the General Language Understanding Evaluation (GLUE) benchmark leaderboard. The BERT-based models exceed the state-of-the-art scores for most of the task-specific benchmarks in the industry (see below).
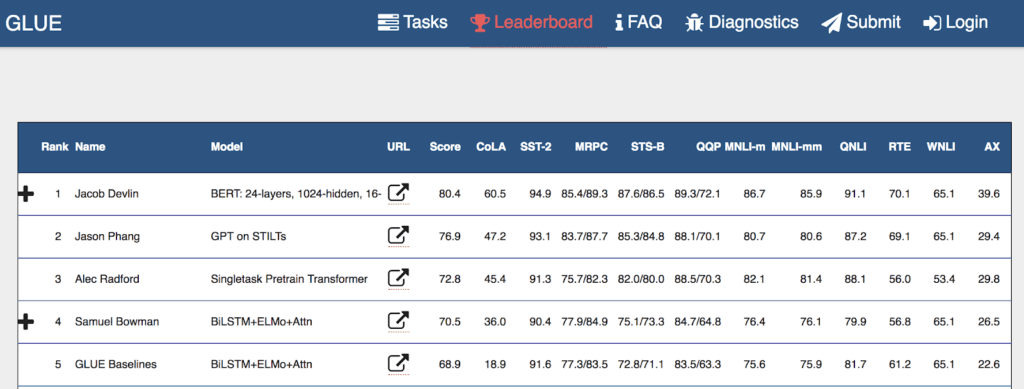
General Language Understanding Evaluation (GLUE) benchmark leaderboard as of November 15, 2018
The thing that sticks out the most to me is the BERT model’s score on question answering. The Stanford Question Answering Dataset (SQuAD v1.1) is one of the industry-standard benchmarks, measuring how accurately an NLP model can provide short answers to a series of questions that pertain to a small article of text. The SQuAD test makers established a human performance benchmark by having a group of people take the same test, annotating and labeling their answers from the various articles. The BERT model with question-answering fine-tuning exceed human performance for the first time ever.
The researchers just recently released the pre-trained models and code for BERT. Here at Capacity, we are eagerly exploring their GitHub repo so we can use the model, transfer-train it with our enterprise and industry-specific tasks and datasets, and plug it into our ensemble of open source and in-house models that power the Capacity platform’s natural language understanding. These are exciting times to be developing NLP systems, so stay tuned as we post new updates.
